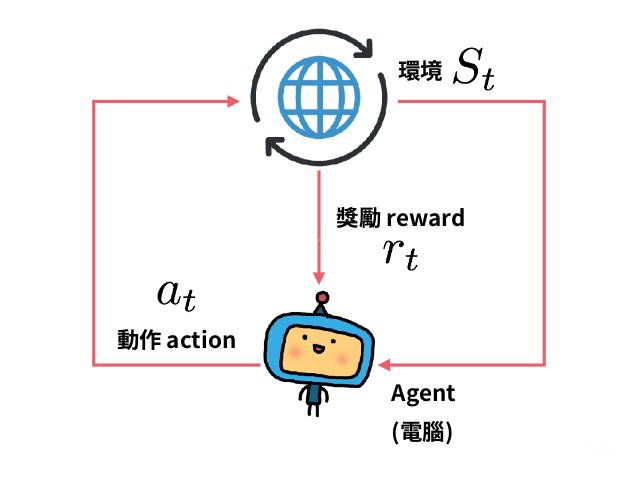
读懂西瓜书 16 : 强化学习
K-摇臂赌博机
探索与利用
探索与利用总是矛盾的, 要使奖赏最大, 就要在探索与利用之间做好权衡.
ϵ-贪心
以 $\epsilon$ 的概率进行探索, 以 $1-\epsilon$ 的概率进行利用.
增量式计算
令 $Q(k)$ 记录摇臂 $k$ 的平均奖赏. 若摇臂 $k$ 被尝试了 $n$ 次, 得到的奖赏是 $v_1,v_2,\dots,v_n$ , 则平均奖赏为
$$
Q(k)=\frac{1}{n}\sum_{i=1}^nv_i
$$
由于如果这样计算的话, 需要记录 $n$ 个奖赏值, 算法效率也不高 ( $\mathcal O(n)$ ) , 所以采用增量式计算.
$$
\begin{aligned}
Q_n(k)&=\frac{1}{n}\big((n-1)\times Q_{n-1}(k)+v_n\big)\\\\
&=Q_{n-1}(k)+\frac{1}{n}\big(v_n-Q_{n-1}(k)\big)
\end{aligned}
$$
这样就只需要记录两个值: 已尝试次数 $n-1$ 以及最近平均奖赏 $Q_{n-1}(k)$ . 算法复杂度也下降到 $\mathcal O(1)$ .
Softmax
$\mathrm{Softmax}$ 可以看做是高维的 $\mathrm{Sigmoid}$ 函数. 使用 $\mathrm{Softmax}$ 可以让那些奖赏更高的摇臂有更高的被选取概率.
$$
p(k) = \frac{\mathrm{e}^{\frac{Q(k)}{\tau}}}{\sum_{i=1}^K\mathrm{e}^{\frac{Q(i)}{\tau}}}
$$
其中 $\tau>0$ 称为 “温度” . 温度趋近于 $0$ , 将倾向于 “仅利用” , 温度趋近于无穷大, 将倾向与 “仅探索” . 我们假设 $k'$ 是奖赏最高的那个摇臂, 那么有
$$
\begin{aligned}
p(k')=\lim_{\tau\to0 }\frac{\mathrm{e}^{\frac{Q(k')}{\tau}}}{\sum_{i=1}^K\mathrm{e}^{\frac{Q(i)}{\tau}}}&=\lim_{\tau\to0 }\frac{1}{1+\sum_{i=1,i\not=k'}^K\frac{\mathrm{e}^{(Q(i)/\tau)}}{\mathrm{e^{(Q(k')/\tau)}}}}\\\\
\end{aligned}
$$
注意到求和的每一项都趋近于 $0$ , 于是有
$$
\begin{aligned}
p(k')=\lim_{\tau\to0 }\frac{\mathrm{e}^{\frac{Q(k)}{\tau}}}{\sum_{i=1}^K\mathrm{e}^{\frac{Q(i)}{\tau}}}&=\lim_{\tau\to0 }\frac{1}{1+\sum_{i=1,i\not=k'}^K\frac{\mathrm{e}^{(Q(i)/\tau)}}{\mathrm{e^{(Q(k')/\tau)}}}}\\\\
&=\frac{1}{1+0}\\\\
&=1
\end{aligned}
$$
趋近于无穷大是相反的一个过程.
有模型学习
策略评估
式 (16.7) 与 (16.8)
对于这两个式子, 注意到
$$
\sum_{a\in A}\pi(x,a)\sum_{x'\in X}P_{x\to x'}^a
$$
计算了下一步到状态 $x'$ 的概率. 而
$$
\sum_{a\in A}\pi(x,a)\sum_{x'\in X}\left(P_{x\to x'}^a\frac{1}{T}R_{x\to x'}^a\right)
$$
则计算了假如下一步转移到状态 $x'$ , 这一步的期望奖赏. (这里用的是 $T$ 步积累奖赏, $\gamma$ 折扣累积奖赏也是类似的) .
策略改进
原来的策略评估只是将所有可能的动作产生的期望以概率求和, 那么为什么不直接选择最好的那个动作呢? 这就叫做策略改进. 由于每一步改进都会变得更好, 于是到最后不能变得再好的时候 (也就是收敛) 时, 就达到了最优策略.
策略迭代与值迭代
第一个算法是将两个部分分开, 效率较低, 而第二个算法同时进行两个部分, 效率较高.
免模型学习
没有模型, 我们就不能方便的计算出每一步的期望了, 因此就要近似的计算.
蒙特卡罗强化学习
通过蒙特卡罗随机游走, 采样出 $n$ 条轨迹, 为了保证每条轨迹都不同, 因此采用了 $\epsilon$-贪心策略, 即以 $1-\epsilon$ 的概率选取确定性的策略 $\pi$ (在这里也可以等价为最优动作) 来作为当前动作, 以 $\epsilon$ 的概率选取随机动作 (同样包括策略 $\pi$ ) . 因此策略 $\pi$ 被选取到的概率是 $1-\epsilon+\frac{\epsilon}{|A|}$ , $A$ 为动作集合.
同策略
同策略即评估和改进的是同一个策略, 即 $\epsilon$-贪心策略. 但是 $\epsilon$-贪心策略本来是帮助策略评估 (走出不同轨迹) 的, 而不是为了最终使用, 于是就有了异策略.
异策略
异策略采用了两种策略, 一种用来评估, 一种用来改进. 其实现原理与拒绝-接受采样差不多.
时序差分学习
由于蒙特卡罗强化学习需要对策略评估后才能做出改进, 而前面的策略迭代与值迭代算法的更新是实时的, 于是蒙特卡罗强化学习方法就显得效率太低, 这是由于没有充分利用强化学习的 $\mathrm{MDP}$ 结构. $\mathrm{MDP}$ 结构的一大特点就是无后效性, 但是蒙特卡罗强化学习的 “全部评估-全部学习” 方法没有很好的利用这一点.
时序差分学习与蒙特卡罗强化学习的差别就在于, 蒙特卡罗强化学习在求平均 (近似期望) 的时候是 “批处理式” 的, 而时序差分学习是 “增量式” 的.
$$
Q_{t+1}^\pi(x,a)=Q_{t}^\pi(x,a)+\frac{1}{t+1}\big(r_t+1-Q_{t}^\pi(x,a)\big)
$$
通常将 $\frac{1}{t+1}$ 替换为系数 $\alpha_{t+1}$ , 在实践中通常令 $\alpha_{t+1}$ 为一个较小的正数值 $\alpha$ . 当然, 这样就不是求平均了, 但是将 $Q_{t}^\pi(x,a)$ 展开, 你会发现系数之和还是 $1$ , 只不过越往后系数越大, 也就是越靠后积累的奖赏越重要, 随着 $\alpha$ 不断增大, 这一特点也在不断扩大. 总而言之, 时序差分学习与蒙特卡罗强化学习的区别就类似于策略迭代与值迭代的两个算法之间的区别.
时序差分学习同样分为同策略与异策略, 与蒙特卡罗强化学习类似.
值函数近似
值函数近似的过程其实就是回归. 用 $\boldsymbol{\theta}^{\mathrm{T}}\boldsymbol{x}$ 和 $\boldsymbol{\theta}^{\mathrm{T}}(\boldsymbol{x},a)$ 来近似 $V^\pi(\boldsymbol{x})$ 和 $Q^\pi(\boldsymbol{x},a)$ , 这样就能解决连续空间有无穷多状态的问题. 至于回归用的算法, 可以自己决定.
模仿学习
直接模仿学习
可以说就是 “预测” 人类专家的动作. 对于离散的动作, 使用的是分类, 对于连续的动作, 使用的是回归. 利用这样的方式学得人类专家的决策, 然后再通过强化学习进一步改进. 也就是 “监督学习” + “强化学习” = “直接模仿学习” .
逆强化学习
直接模仿学习是 “直接” 学习现有的范例, 然后根据已有的奖赏函数继续学习. 而逆强化学习的 “逆” 就体现在, 它根据现有的范例, 反推出奖赏函数, 然后利用反推出的奖赏函数学习. 而反推出的奖赏函数要符合什么性质呢, 就是要保证在此奖赏函数下, 范例就是最优策略. 由于所有策略几乎不可能都尝试一遍, 因此往往采用迭代的方式, 先随机生成一个策略然后求取奖赏函数, 然后根据奖赏函数再求取策略, 如此反复直到策略和奖赏函数都符合范例.